在探究基因表达、基因拷贝数等连续变量对癌症病人的预后情况的影响时,我不得不面对和处理的主要问题是如何对这种连续型的变量进行分组,然后进行相应的生存分析。
做科研分析的朋友可能都比较了解,针对变量数值分组,一般是采用中位数、四分位数或者均值这些基本描述统计量。如果更细致地,可以按百分比,例如Top/Bottom 5%啊,10%啊之类的进行划分。
我们先来看怎么实现,然后再谈谈我自己的理解和评价。
生存分析最最关键的两个变量是生存事件和存活时间,前者是指一位病患是死了还是不知道是死是活了,前者一般用1表示,后者用0,其中后者常被称为截尾事件,要么就是研究周期到了,病人还没死;要么是找不到人了。我这里不是在侃概念,述说得也并不一定精准,详细了解就找谷歌度娘,我不再赘述。
科研分析的目的大抵都可以归根到找差异,你搞出来的跟别人搞出来的不一样,你就有话语权了,可以发文章。所以生存分析第三个必不可少的变量是组别变量,用来对比和探寻差异。
有的时候组别不明自显,比如我们要分析某个癌症组织和正常组织的差异,那么划分组别的方式自然就很明显了,而且在实验或分析设计之时就能确定。这种数据用来进行生存分析是最简单的,标准的代码一套,看结果就可以了。
如果你是想进行这样的分析,百度一下相信有不少博文可以解决你的这个问题。用R来做,不外乎以下几步:
1 | # 载入分析和画图包 |
这里画图函数涉及一些参数的设定,可以参考怎么画出好看的生存曲线这篇文章。
如果我们想要将连续型变量进行生存对比分析,显然我们要在构建生存模型之前将组别划分好。
这样的问题是最让人讨厌却又难以避而不见的,像基因表达对预后的影响就以这样的问题呈现出来,做过几次之后我对这种频繁改动组别设定的操作感到厌烦。
为了提升操作的效率,我花时间将分组和画图两个过程都写成了函数的形式,放在Gist上,有需要的可以下载使用。
第一个分组函数尽量不要改动,第二个画图函数涉及比较多的参数设定,使用时自由度更高,可以根据自己的需要进行修改。
我们先查看我载入的样例数据:
1 | head(df) |
1 | ## samples expression OS OS_IND |
载入写好的函数脚本:
1 | source("~/Desktop/groupSurvival.R") |
1 | ## function (df, event = "OS_IND", time = "OS", var = NULL, time.limit = NULL, |
1 | args(plot_surv) |
1 | # function (os_mat, cutoff = NULL, pval = TRUE, ...) |
最重要的groupSurvival函数,一系列的参数都有含义,包括指定最重要的三个变量,设定分组的方法,组名,甚至我还在内部写了一个函数去根据步长计算对应的p值(最小p值和对应的时间会返回为结果列表的一部分)。
使用函数对基因表达进行分组,分组方式是median中位数。
1 | res <- groupSurvival(df=df, event="OS_IND", time="OS", var="expression",method="median") |
画图看看:
1 | plot_surv(res$data) |
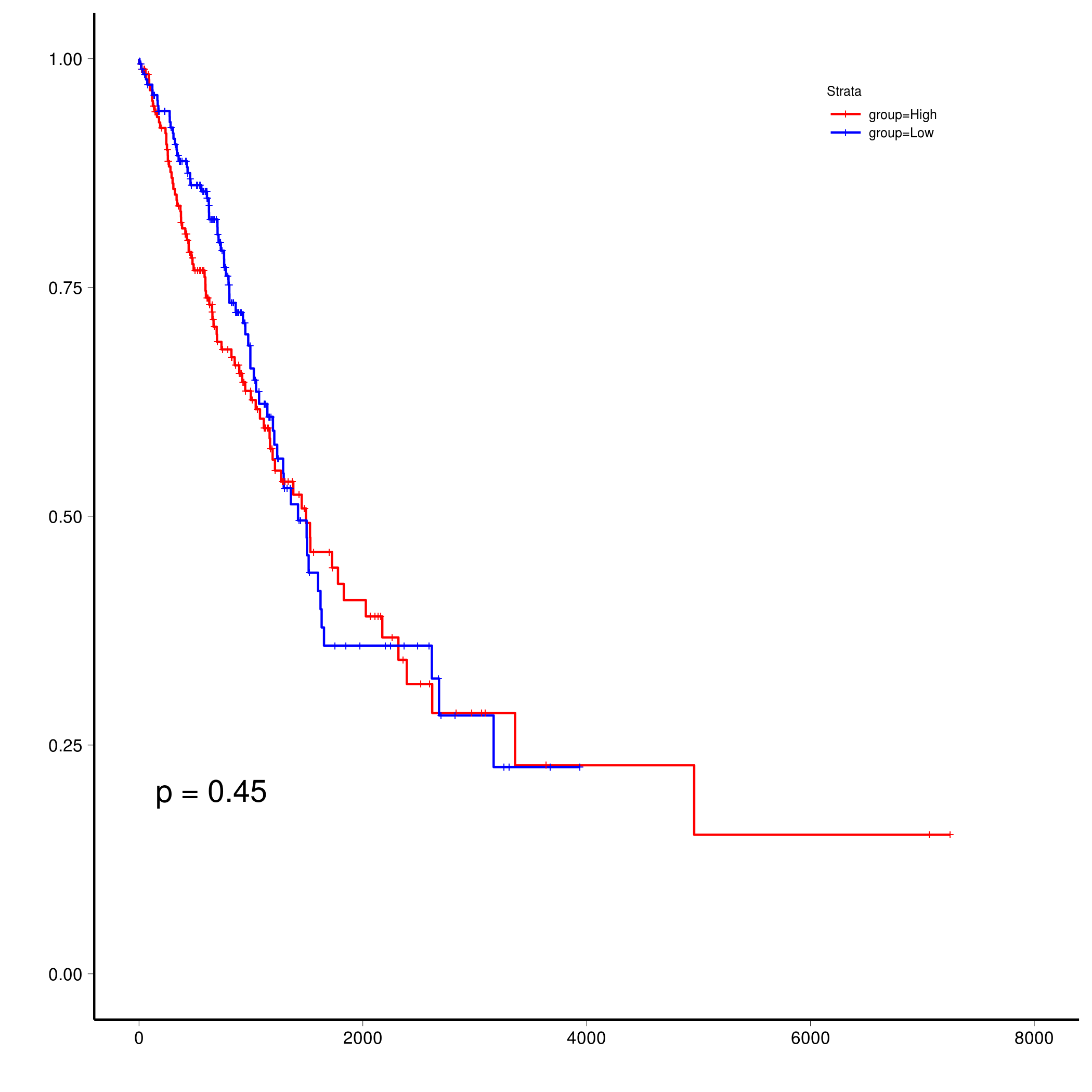
设置一个时间阈值:
1 | plot_surv(res$data, cutoff = 3000) |
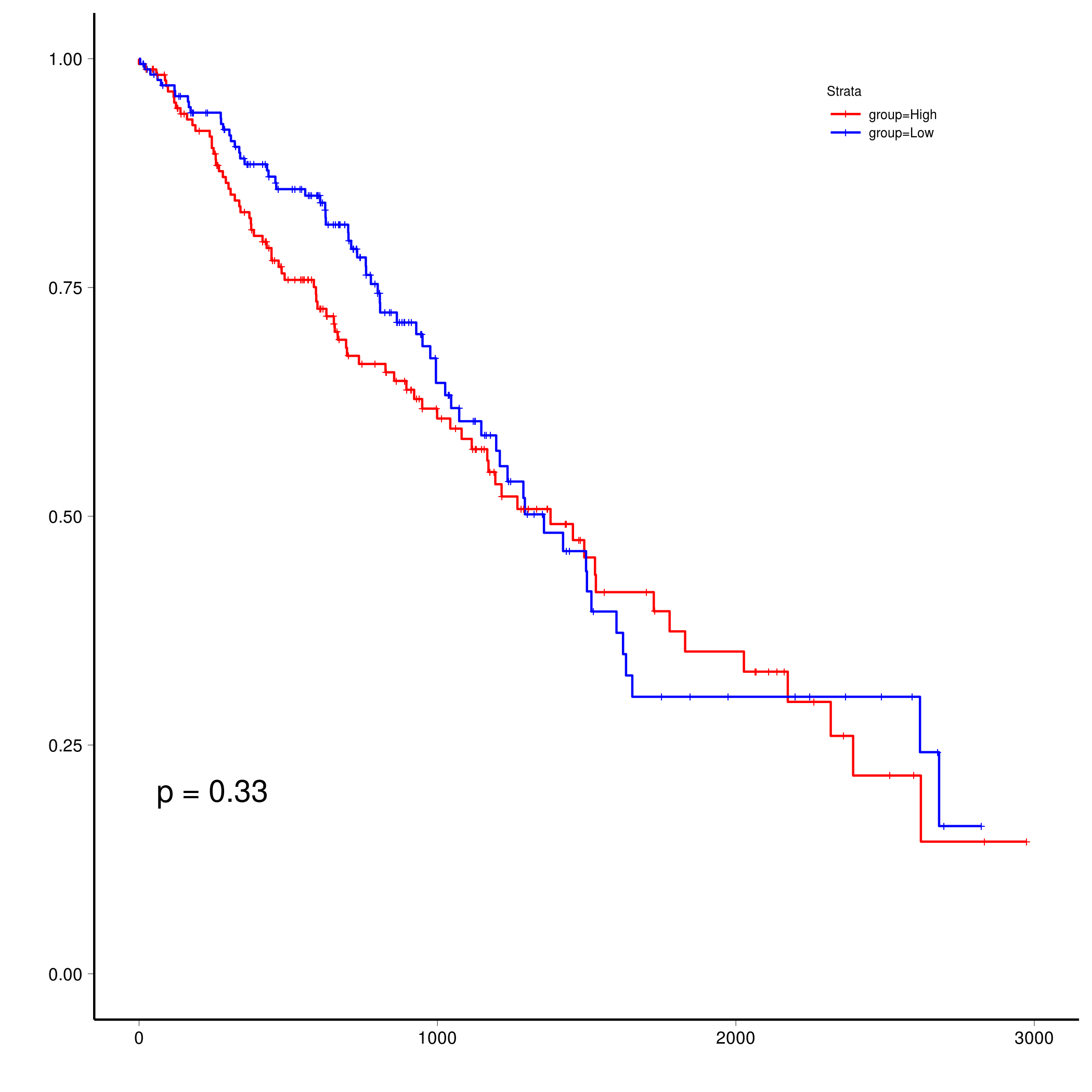
使用百分比(上下百分之多少),并确定使用的比例(1表示100%)分组并进行绘图。
1 | res <- groupSurvival(df=df, event="OS_IND", time="OS", var="expression",method="percent", percent = 0.1) |
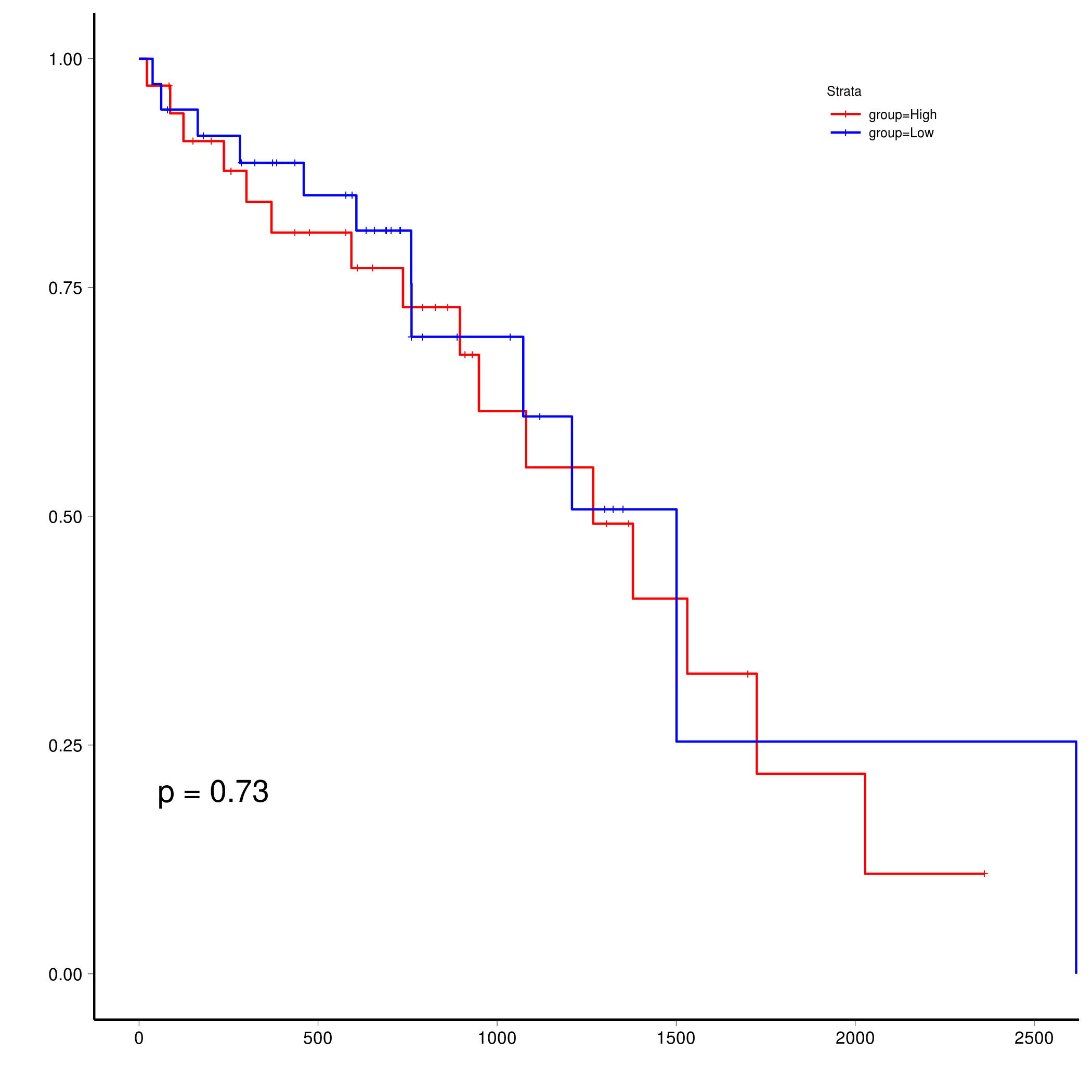
如果你有一些R的编程基础,完全可以基于这两个函数将所有的方法算一遍,然后再去查看结果,确定合适的分组方式。
最后,我们到底应该根据结果选择方法、还是选择方法之后就认定了结果,这是悬在这类分析中的一把利剑。所谓的差异到底是什么?我们在进行分析时需要有自己的道德和专业两重标准。
无论大家是否有共识,做好自己足矣。